TL;DR: I’m shutting down the twitfeeder project (it was on lifesupport for a long time) so I mirrored a technical article from the blog in the hope that it might be useful for somebody someday.
Proxying URL fetch requests from the Google App Engine
Hosting on the Google App Engine means giving up a lot controls: your
application will run on some machines in one of Google’s datacenters,
use some other machines to store data and use yet an other set of
machines to talk to the outside world (send/receive emails, fetch URLs,
etc). You don’t know the exact identity of these machines (which for
this article means their external IP address), and even though you can
find out some of the details (for example by fetching the ipchicken page
and parsing the result or by sending an e-mail and looking at the
headers), there is no guarantee made that the results are repeatable
(ie. if you do it again and again you will get the same result) in the
short or long run. While one might not care about such details most of
the time, there are some corner cases where it would be nice to have a
predictable and unique source address:
- You might
worry that some of the exit points get blocked because other
applications on the Google App Engine have an abusive behavior - You might want a single exit point so that you can “debug” your traffic at a low (network / tcpdump) level
- And finally, the main reason for which the Twit Feeder uses it: some third-party services (like Twitter or Delicious) use the source IP to whitelist requests to their API
To
be fair to the GAE Architects: the above considerations don’t affect
the main usecase and are more of a cornercase if we look at the average
application running on the GAE. Also, having so few commitments (ie.
they don’t stipulate things like “all the URL fetches will come from the
10.0.0.1/24 netblock”) means that they are free to move things around
(even between datacenters) to optimize uptime and performance which in
turn benefits the application owners and users.
Back to
our scenario: the solution is to introduce an intermediary which has a
static and well known IP and let it do all the fetching. Ideally I would
have installed Squid and and
be done with it, but the URL fetch service doesn’t have support for
proxies currently. So the solution I came up with looks like this:
- Get
a VPS server. I would recommend one which gives you more bandwidth
rather than more CPU / memory / disk. It is also a good idea to get one
in the USA to minimize latency from/to the Google datacenters. I’m
currently using VPSLink and I didn’t had any problems (full disclosure: that is a referral link and you should get 10% off for lifetime if you use it). - Install Apache + PHP on it
- Use a simple PHP script to fetch the page encoded in a query parameter using the php_curl extension.
To spice up this blogpost ;-), here is a diagram of the process:
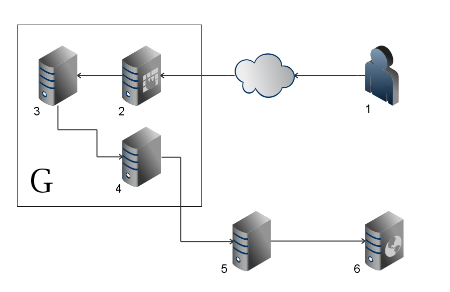
A couple of points:
- Taking
care of a VPS can be challenging, especially if you aren’t a Linux
user. However failing to do so can result in it being taken over by
malicious individuals. Consider getting a managed VPS. Also, three quick
security tips: use strong passwords. move the SSH server to a
non-standard port and configure your firewall to be as restrictive as
possible (deny everything, and open ports to only a limited number of IP
addresses). - Yes, this introduces a single point of failure
into your application, so plan accordingly (while your application is
small, this shouldn’t be a problem – as it grows you can get two VPS’s
at two different data centers for example for added reliability). - The
traffic between Google and your VPS can be encrypted using TLS (HTTPS).
The good news is that the URL fetcher service doesn’t check the
certificates, so you can use self-signed ones. The bad news is that the
URL fetcher doesn’t check the certificates, so a determined attacker can
relatively easily man-in-the-middle you (but it protects the data from
the casual sniffer). - Be aware that you need to budget for
double of the amount of traffic you estimate using at the VPS (because
it needs to first download it and then upload it back to Google). The
URL fetcher service does know how to use gzip compression, so if you are
downloading mainly text, you shouldn’t have a bandwidth problem. - PHP
might seem like an unusual choice of language, given how most GAE users
have experience in either Python or Java, but there are a lot of
tutorials out there on how to install it (and on modern Linux
distribution it can be done in under 10 minutes with the help of the
package manager) and it was the one I was most comfortable with as an
Apache module.
Without further ado, here are the relevant sourcecode snippets (which I hereby release into the public domain):
The PHP script:
<?php
error_reporting(0);
require 'privatedata.php';
if ($AUTH != @$_SERVER['HTTP_X_SHARED_SECRET']) {
header("HTTP/1.0 404 Not Found");
exit;
}
$url = @$_GET['q'];
if (!isset($url)) {
header("HTTP/1.0 404 Not Found");
exit;
}
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_ENCODING, '');
curl_setopt($ch, CURLOPT_TIMEOUT, 30);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, false);
if (isset($_SERVER['HTTP_USER_AGENT'])) {
curl_setopt($ch, CURLOPT_USERAGENT, $_SERVER['HTTP_USER_AGENT']);
}
if (isset($_SERVER['PHP_AUTH_USER']) && isset($_SERVER['PHP_AUTH_PW'])) {
curl_setopt($ch, CURLOPT_USERPWD, "{$_SERVER['PHP_AUTH_USER']}:{$_SERVER['PHP_AUTH_PW']}");
}
if (count($_POST) > 0) {
curl_setopt($ch, CURLOPT_POST, true);
$postfields = array();
foreach ($_POST as $key => $val) {
$postfields[] = urlencode($key) . '=' . urlencode($val);
}
curl_setopt($ch, CURLOPT_POSTFIELDS, implode('&', $postfields));
}
$headers = array();
function header_callback($ch, $header) {
global $headers;
// we add our own content encoding
// also, the content length might vary because of this
if (false === stripos($header, 'Content-Encoding: ')
&& false === stripos($header, 'Content-Length: ')
&& false === stripos($header, 'Transfer-Encoding: ')) {
$headers[] = $header;
}
return strlen($header);
}
curl_setopt($ch, CURLOPT_HEADERFUNCTION, 'header_callback');
$output = curl_exec($ch);
if (FALSE === $output) {
header("HTTP/1.0 500 Server Error");
print curl_error($ch);
exit;
}
curl_close($ch);
foreach ($headers as $header) {
header($header);
}
print $output;
The “privatedata.php” file looks like this:
<?php
$AUTH = '23tqhwfgj2qbherhjerj';
Two
separate files are being used to avoid submitting the password to the
source repository, while still keeping all the sourcecode open.
Now with the code in place, you can test it using curl:
curl --compressed -v -H 'X-Shared-Secret: 23tqhwfgj2qbherhjerj' 'http://127.0.0.1:1483/fetch_url.php?q=http%3A//identi.ca/api/help/test.json
As
you can see, a custom header is used for authentication. An other
security measure is to use a non-standard port. Limiting the requests to
the IPs of the Google datacenter from the firewall would be the ideal
solution, but given that this was the problem we are trying to solve in
the first place (the Google datacenters not having an officially
announced set of IP addresses), this doesn’t seem possible.
Finally, here is the Python code to use the script from withing an application hosted on the GAE:
from urllib import quote
from google.appengine.api import urlfetch
# ...
fetch_headers['X-Shared-Secret'] = '23tqhwfgj2qbherhjerj'
result = urlfetch.fetch(url='http://127.0.0.1:1483/fetch_url.php?q=%s' % quote(url), payload=data,
method=urlfetch.POST if data else urlfetch.GET,
headers=fetch_headers, deadline=timeout, follow_redirects=False)
A little more discussion about the code:
- The
method of using a custom header for authorization was chosen, since the
forwarding of authentication data (ie. the “Authorization” header) was
needed (specifically this is what the Twitter API uses for verifying
identity) - Speaking of things the script forwards: it does
forward the user agent and any POST data if present. The forwarding of
other headers could be quite easily be added. - Passing
variables in a GET request is also supported (they would be
double-encoded, but that shouldn’t be a concern in but the most extreme
cases) - If we are talking about sensitive data, cURL (and the cURL extension for PHP) has the ability to fetch HTTPS content and to verify the certificates.
While
this method might look cumbersome, in practice I found it to work quite
well. Hopefully this information will help others facing the same
problem. A final note: if you have questions about the code or about
other aspects, post them in the comments. I will try to answer them as
fast as possible. I’m also considering launching a “proxy service” for
GAE apps to make this process much more simpler (abstracting away the
setup and administration of the VPS), so if you would be interested in
paying a couple of bucks for such a service, please contact me either
directly or trough the comments.